


Microsoft’s DeBERTa (Decoding-enhanced BERT with disentangled attention) has surpassed the natural language understanding baseline set at par with human performance in the SuperGlue benchmark. While the human baseline stands at 89.8 macro-average scores, the DeBERTa ensemble scored 90.3. The model used only half of the training data as compared to RoBERTa.
Microsoft’s DeBERTa uses the neural architectures of Transformer (48 transformers layers) that has 1.5 billion parameters. Like other transformer-based language models, DeBERTa is pre-tuned on considerably large datasets to learn universal language representations. Then, the model is fine-tuned to various downstream NLU tasks like Choice Of Plausible Alternatives (COPA), Multi-Sentence Reading Comprehension (MultiRC), Recognizing Textual Entailment (RTE), Word-in-Context (WiC), Winograd Schema Challenge (WSC), and reading comprehension with commonsense reasoning.
The Microsoft researchers used three techniques to build upon RoBERTa: –
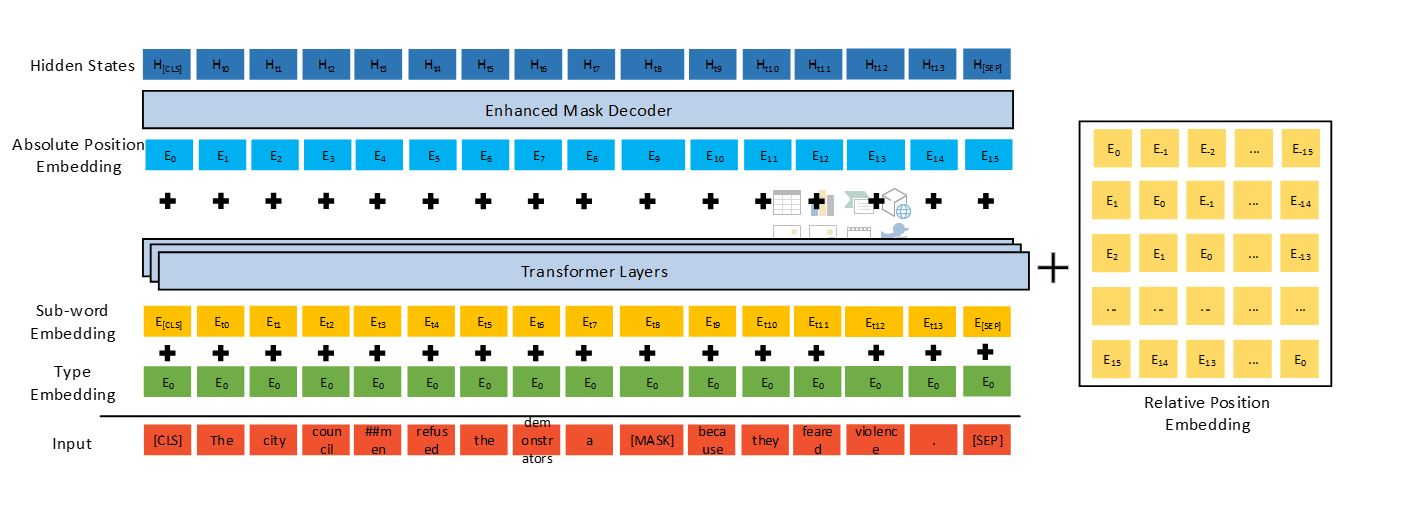
- Disentangled attention mechanism (contextual and positional information is preserved for each word by two vectors separately)
- Enhanced mask decoder (the training comprises of predicting the correct word for the missing place)
- Virtual adversarial training method (for fine-tuning to learn more robust word representation)
Separate encoding for context and position correctly assigns attention weights between words that account for any dependencies. The enhanced masked decoder forces the model to predict words for a mask by accounting for previous words. The idea is to make the model aware of these words’ absolute positions, which is critical to handle syntactic nuances.
Also Read: IIsc Invites Application For Its New Deep Learning Specialisation
For models as big as DeBERTa, improving models’ generalization towards adversarial examples is a challenge. Therefore, the researchers at Microsoft developed the Scale-Invariant-Fine-Tuning (SiFT) method. The adversarial perturbations are applied to the normalized word embeddings, and the model is regularized to produce the same output on a task before adding perturbations of that example.
Microsoft’s DeBERTa will be a part of the Microsoft Turing natural language representation model (Turing NLRv4). These models will serve Microsoft products like Bing, Office, Dynamics, Azure Cognitive Services, chatbots, recommendation, question answering, search, personal assist, customer support automation, and content generation.
